add performance
This commit is contained in:
parent
ff1f7bdde4
commit
ec0b891bf7
204
README.md
204
README.md
|
|
@ -1,6 +1,6 @@
|
|||
# Xcdat: Fast compressed trie dictionary library
|
||||
# Xcdat: Fast compressed trie dictionary library
|
||||
|
||||
**Xcdat** is a C++17 header-only library of a fast compressed string dictionary based on an improved double-array trie structure described in the paper: [Compressed double-array tries for string dictionaries supporting fast lookup](https://doi.org/10.1007/s10115-016-0999-8), *Knowledge and Information Systems*, 2017, available at [here](https://kampersanda.github.io/pdf/KAIS2017.pdf).
|
||||
**Xcdat** is a C++17 header-only library of a fast compressed string dictionary based on an improved double-array trie structure described in the paper: [Compressed double-array tries for string dictionaries supporting fast lookup](https://doi.org/10.1007/s10115-016-0999-8), *Knowledge and Information Systems*, 2017, available [here](https://kampersanda.github.io/pdf/KAIS2017.pdf).
|
||||
|
||||
## Table of contents
|
||||
|
||||
|
|
@ -16,7 +16,7 @@
|
|||
|
||||
## Features
|
||||
|
||||
- **Compressed string dictionary.** Xcdat implements a (static) *compressed string dictioanry* that stores a set of strings (or keywords) in a compressed space while supporting several search operations [1,2]. For example, Xcdat can store an entire set of English Wikipedia titles at half the size of the raw data.
|
||||
- **Compressed string dictionary.** Xcdat implements a (static) *compressed string dictioanry* that stores a set of strings (or keywords) in a compressed space while supporting several search operations [1,2]. For example, Xcdat can store an entire set of English Wikipedia titles at half the size of the raw data. (see [Performance](#performance))
|
||||
- **Fast and compact data structure.** Xcdat employs the *double-array trie* [3] known as the fastest trie implementation. However, the double-array trie resorts to many pointers and consumes a large amount of memory. To address this, Xcdat applies the *XCDA* method [2] that represents the double-array trie in a compressed format while maintaining the fast searches.
|
||||
- **Cache efficiency.** Xcdat employs a *minimal-prefix trie* [4] that replaces redundant trie nodes into strings to reduce random access and to improve locality of references.
|
||||
- **Dictionary encoding.** Xcdat maps `N` distinct keywords into unique IDs from `[0,N-1]`, and supports the two symmetric operations: `lookup` returns the ID corresponding to a given keyword; `decode` returns the keyword associated with a given ID. The mapping is so-called *dictionary encoding* (or *domain encoding*) and is fundamental in many DB applications as described by Martínez-Prieto et al [1] or Müller et al. [5].
|
||||
|
|
@ -30,7 +30,7 @@
|
|||
|
||||
You can download, compile, and install Xcdat with the following commands.
|
||||
|
||||
```
|
||||
```sh
|
||||
$ git clone https://github.com/kampersanda/xcdat.git
|
||||
$ cd xcdat
|
||||
$ mkdir build
|
||||
|
|
@ -40,7 +40,7 @@ $ make -j
|
|||
$ make install
|
||||
```
|
||||
|
||||
Or, since this library consists only of header files, you can easily install it by passing through the path to the directory `include`.
|
||||
Or, since this library consists only of header files, you can easily install it by passing the include path to the directory `include`.
|
||||
|
||||
### Requirements
|
||||
|
||||
|
|
@ -182,15 +182,15 @@ int main() {
|
|||
"Mac_Mini", "Mac_Pro", "iMac", "iPad", "iPhone", "iPhone_SE",
|
||||
};
|
||||
|
||||
// The input keys must be sorted and unique (although they have already satisfied in this case).
|
||||
// The input keys must be sorted and unique (already satisfied in this case).
|
||||
std::sort(keys.begin(), keys.end());
|
||||
keys.erase(std::unique(keys.begin(), keys.end()), keys.end());
|
||||
|
||||
// The trie dictionary type
|
||||
using trie_type = xcdat::trie_7_type;
|
||||
// using trie_type = xcdat::trie_8_type;
|
||||
// using trie_type = xcdat::trie_15_type;
|
||||
// The trie dictionary type from the four types
|
||||
using trie_type = xcdat::trie_8_type;
|
||||
// using trie_type = xcdat::trie_16_type;
|
||||
// using trie_type = xcdat::trie_7_type;
|
||||
// using trie_type = xcdat::trie_15_type;
|
||||
|
||||
// The dictionary filename
|
||||
const char* tmp_filename = "dic.bin";
|
||||
|
|
@ -207,6 +207,9 @@ int main() {
|
|||
// Load the trie dictionary on memory.
|
||||
const auto trie = xcdat::load<trie_type>(tmp_filename);
|
||||
|
||||
// Or, you can set the continuous memory block via a memory-mapped file.
|
||||
// const auto trie = xcdat::mmap<trie_type>(mapped_data);
|
||||
|
||||
// Basic statistics
|
||||
std::cout << "Number of keys: " << trie.num_keys() << std::endl;
|
||||
std::cout << "Number of trie nodes: " << trie.num_nodes() << std::endl;
|
||||
|
|
@ -249,7 +252,7 @@ int main() {
|
|||
std::cout << "}" << std::endl;
|
||||
}
|
||||
|
||||
// Enumerate all the keys (in lex order).
|
||||
// Enumerate all the keys (in lexicographical order).
|
||||
{
|
||||
std::cout << "Enumerate() = {" << std::endl;
|
||||
auto itr = trie.make_enumerative_iterator();
|
||||
|
|
@ -336,6 +339,9 @@ The trie dictionary class provides the following functions.
|
|||
template <class BcVector>
|
||||
class trie {
|
||||
public:
|
||||
//! The type identifier.
|
||||
static constexpr std::uint32_t type_id;
|
||||
|
||||
//! Default constructor
|
||||
trie() = default;
|
||||
|
||||
|
|
@ -477,7 +483,7 @@ class trie {
|
|||
};
|
||||
```
|
||||
|
||||
### I/O handlers
|
||||
### I/O utilities
|
||||
|
||||
`xcdat.hpp` provides some functions for handling I/O operations.
|
||||
|
||||
|
|
@ -491,6 +497,7 @@ template <class Trie>
|
|||
Trie load(const std::string& filepath);
|
||||
|
||||
//! Save the trie dictionary to the file and returns the file size in bytes.
|
||||
//! The identifier of the trie type will be written in the first 4 bytes.
|
||||
template <class Trie>
|
||||
std::uint64_t save(const Trie& idx, const std::string& filepath);
|
||||
|
||||
|
|
@ -498,17 +505,149 @@ std::uint64_t save(const Trie& idx, const std::string& filepath);
|
|||
template <class Trie>
|
||||
std::uint64_t memory_in_bytes(const Trie& idx);
|
||||
|
||||
//! Get the flag indicating the trie type, embedded by the function 'save'.
|
||||
//! The flag corresponds to trie::l1_bits and will be used to detect the trie type from the file.
|
||||
std::uint32_t get_flag(const std::string& filepath);
|
||||
|
||||
//! Load the keywords from the file.
|
||||
std::vector<std::string> load_strings(const std::string& filepath, char delim = '\n');
|
||||
//! Get the identifier of the trie type embedded by the function 'save'.
|
||||
//! The identifier corresponds to trie::type_id and will be used to detect the trie type.
|
||||
std::uint32_t get_type_id(const std::string& filepath);
|
||||
```
|
||||
|
||||
## Performance
|
||||
|
||||
To be added...
|
||||
We compared the performance of Xcdat with those of other selected dictionary libraries written in C++.
|
||||
|
||||
### Implementations
|
||||
|
||||
- Our compressed double-array tries [2]
|
||||
- [xcdat<8>](https://github.com/kampersanda/xcdat/blob/master/include/xcdat.hpp): `xcdat::trie_8_type`
|
||||
- [xcdat<16>](https://github.com/kampersanda/xcdat/blob/master/include/xcdat.hpp): `xcdat::trie_16_type`
|
||||
- [xcdat<7>](https://github.com/kampersanda/xcdat/blob/master/include/xcdat.hpp): `xcdat::trie_7_type`
|
||||
- [xcdat<15>](https://github.com/kampersanda/xcdat/blob/master/include/xcdat.hpp): `xcdat::trie_15_type`
|
||||
- Other double-array tries
|
||||
- [darts](http://chasen.org/~taku/software/darts/): Double-array trie [3].
|
||||
- [darts-clone](https://github.com/s-yata/darts-clone): Compact double-array trie [10].
|
||||
- [cedar](http://www.tkl.iis.u-tokyo.ac.jp/~ynaga/cedar/): Dynamic double-array reduced trie [11,12]
|
||||
- [cedarpp](http://www.tkl.iis.u-tokyo.ac.jp/~ynaga/cedar/): Dynamic double-array prefix trie [11,12]
|
||||
- [dastrie](http://www.chokkan.org/software/dastrie/): Compact double-array prefix trie [10]
|
||||
- Succinct tries
|
||||
- [tx](https://github.com/hillbig/tx-trie): LOUDS trie [13]
|
||||
- [marisa](https://github.com/s-yata/marisa-trie): LOUDS nested patricia trie [14]
|
||||
- [fst](https://github.com/kampersanda/fast_succinct_trie): Fast succinct prefix trie [15]
|
||||
- [pdt](https://github.com/ot/path_decomposed_tries): Centroid path-decomposed trie with RePair [16]
|
||||
- Tessil's string containers
|
||||
- [hat-trie](https://github.com/Tessil/hat-trie/): HAT-trie [17]
|
||||
- [array-hash](https://github.com/Tessil/array-hash): Array hashing [18]
|
||||
|
||||
### Environments
|
||||
|
||||
- **Machine:** MacBook Pro (13-inch, 2019)
|
||||
- **OS:** macOS Catalina (version 10.15)
|
||||
- **Processor:** 2.4 GHz Quad-Core Intel Core i5
|
||||
- **Memory:** 16 GB 2133 MHz LPDDR3
|
||||
- **Compiler:** AppleClang (version 12.0.0)
|
||||
- **Optimization flags:** `-O3 -march=native`
|
||||
|
||||
### Datasets
|
||||
|
||||
- Natural language corpus
|
||||
- **IPA:** 325,871 different Japanese words from [IPAdic](https://taku910.github.io/mecab/) (3.7 MiB, 11.9 bytes/key)
|
||||
- **Wiki:** 14,130,439 different [English Wikipedia titles](https://dumps.wikimedia.org/) on 2018-09-20 (285 MiB, 21.2 bytes/key)
|
||||
- [Askitis's datasets](http://web.archive.org/web/20120206015921/http://www.naskitis.com/)
|
||||
- **Distinct:** 28,772,169 different english words (290 MiB, 10.6 bytes/key)
|
||||
- **Url:** 1,289,458 different URL strings (44 MiB, 36.2 bytes/key)
|
||||
|
||||
### Approach
|
||||
|
||||
We constructed a dictionary from a dataset and measured the elapsed time. The dynamic dictionaries, Cedar and Tessil's containers, were constructed by inserting sorted keywords. Each keyword is associated with a unique ID of a 4-byte integer. Since all the libraries support serialization of the data structure, we measured the file size as the memory usage.
|
||||
|
||||
The time to lookup IDs from keywords was measured for 1,000 query keywords randomly sampled from each the dataset. Also, for some libraries supporting to decode keywords from IDs, the time was measured for the 1,000 IDs corresponding to the query keywords. We took the best result of 10 runs.
|
||||
|
||||
The code of the benchmark can be found [here](https://github.com/kampersanda/fast_succinct_trie/tree/master/bench).
|
||||
|
||||
### Results
|
||||
|
||||
#### Plots: memory vs. lookup
|
||||
|
||||
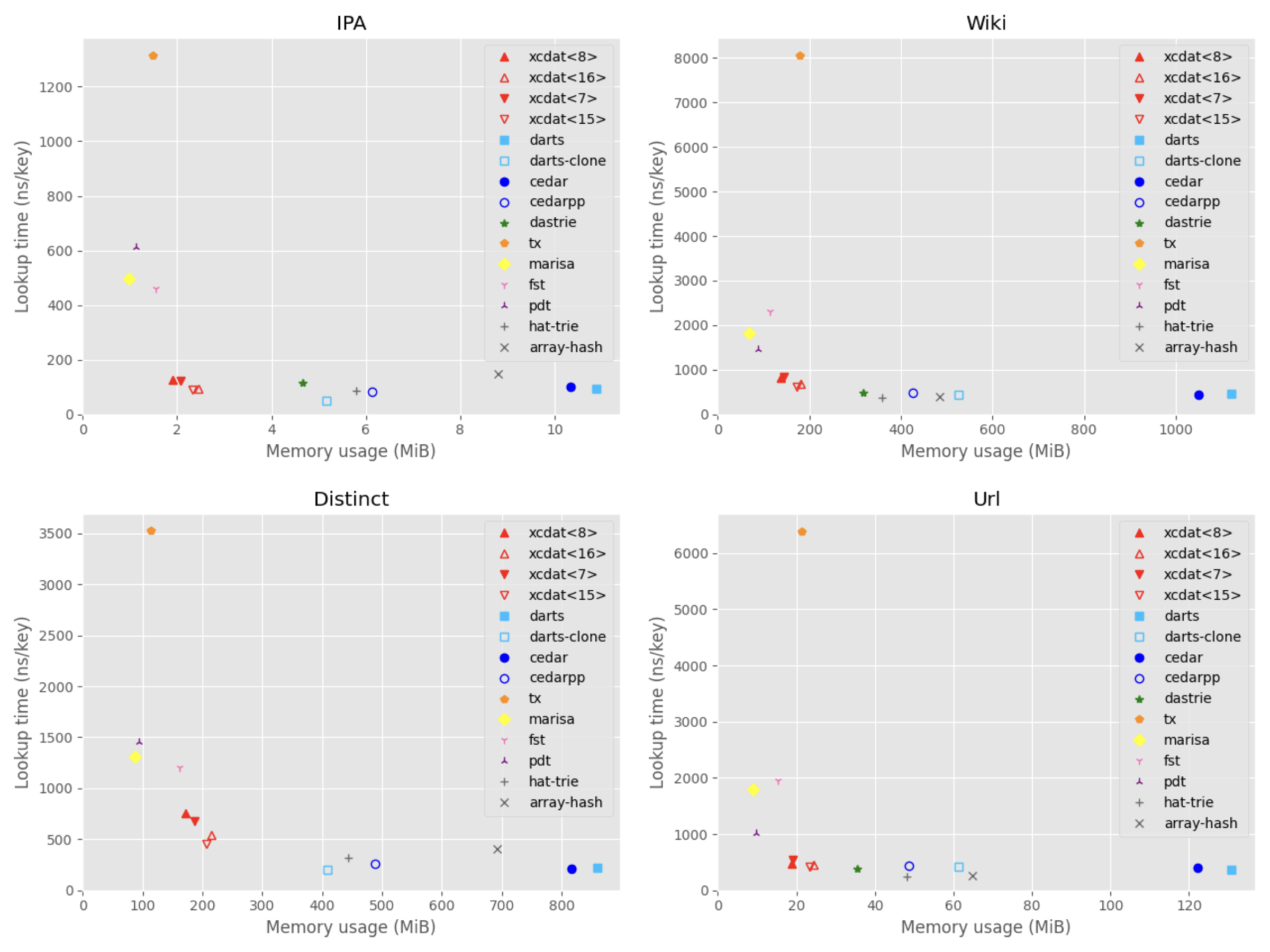
|
||||
|
||||
#### Table: IPA
|
||||
|
||||
| Library | Data structure | Memory (MiB) | Build (ns/key) | Lookup (ns/key) | Decode (ns/id) |
|
||||
| ----------- | ----------------------------------------- | -----------: | -------------: | --------------: | -------------: |
|
||||
| xcdat<8> | XCDA prefix trie | 1.9 | 271 | 124 | 198 |
|
||||
| xcdat<16> | XCDA prefix trie | 2.5 | 257 | 94 | 144 |
|
||||
| xcdat<7> | XCDA prefix trie | 2.1 | 288 | 122 | 192 |
|
||||
| xcdat<15> | XCDA prefix trie | 2.3 | 259 | 89 | 139 |
|
||||
| darts | Double-array trie | 10.9 | 725 | 94 | n/a |
|
||||
| darts-clone | Compact double-array trie | 5.2 | 231 | 52 | n/a |
|
||||
| cedar | Double-array reduced trie (dyn) | 10.3 | 150 | 101 | n/a |
|
||||
| cedarpp | Double-array prefix trie (dyn) | 6.1 | 171 | 83 | n/a |
|
||||
| dastrie | Compact double-array prefix trie | 4.7 | 233 | 117 | n/a |
|
||||
| tx | LOUDS trie | 1.5 | 256 | 1315 | 1289 |
|
||||
| marisa | LOUDS nested patricia trie | 1.0 | 466 | 498 | 385 |
|
||||
| fst | Fast succinct prefix trie | 1.6 | 529 | 460 | n/a |
|
||||
| pdt | Centroid path-decomposed trie with RePair | 1.1 | 1436 | 614 | 716 |
|
||||
| hat-trie | HAT-trie (dyn) | 5.8 | 330 | 87 | n/a |
|
||||
| array-hash | Array hashing (dyn) | 8.8 | 476 | 147 | n/a |
|
||||
|
||||
#### Table: Wiki
|
||||
|
||||
| Library | Data structure | Memory (MiB) | Build (ns/key) | Lookup (ns/key) | Decode (ns/id) |
|
||||
| ----------- | ----------------------------------------- | -----------: | -------------: | --------------: | -------------: |
|
||||
| xcdat<8> | XCDA prefix trie | 139 | 672 | 826 | 1173 |
|
||||
| xcdat<16> | XCDA prefix trie | 182 | 672 | 679 | 902 |
|
||||
| xcdat<7> | XCDA prefix trie | 144 | 674 | 829 | 1153 |
|
||||
| xcdat<15> | XCDA prefix trie | 174 | 668 | 619 | 821 |
|
||||
| darts | Double-array trie | 1121 | 1795 | 452 | n/a |
|
||||
| darts-clone | Compact double-array trie | 525 | 584 | 450 | n/a |
|
||||
| cedar | Dynamic double-array reduced trie | 1049 | 210 | 445 | n/a |
|
||||
| cedarpp | Dynamic double-array prefix trie | 425 | 174 | 484 | n/a |
|
||||
| dastrie | Compact double-array prefix trie | 317 | 387 | 488 | n/a |
|
||||
| tx | LOUDS trie | 178 | 674 | 8062 | 7086 |
|
||||
| marisa | LOUDS nested patricia trie | 69 | 1078 | 1818 | 1515 |
|
||||
| fst | Fast succinct prefix trie | 114 | 1132 | 2309 | n/a |
|
||||
| pdt | Centroid path-decomposed trie with RePair | 89 | 4242 | 1456 | 1514 |
|
||||
| hat-trie | HAT-trie | 358 | 361 | 368 | n/a |
|
||||
| array-hash | Array hashing | 484 | 927 | 385 | n/a |
|
||||
|
||||
#### Table: Distinct
|
||||
|
||||
| Library | Data structure | Memory (MiB) | Build (ns/key) | Lookup (ns/key) | Decode (ns/id) |
|
||||
| ----------- | ----------------------------------------- | -----------: | -------------: | --------------: | -------------: |
|
||||
| xcdat<8> | XCDA prefix trie | 172 | 347 | 757 | 1017 |
|
||||
| xcdat<16> | XCDA prefix trie | 215 | 357 | 543 | 742 |
|
||||
| xcdat<7> | XCDA prefix trie | 186 | 371 | 676 | 1003 |
|
||||
| xcdat<15> | XCDA prefix trie | 206 | 339 | 451 | 691 |
|
||||
| darts | Double-array trie | 859 | 1990 | 225 | n/a |
|
||||
| darts-clone | Compact double-array trie | 409 | 251 | 198 | n/a |
|
||||
| cedar | Dynamic double-array reduced trie | 817 | 127 | 213 | n/a |
|
||||
| cedarpp | Dynamic double-array prefix trie | 488 | 164 | 261 | n/a |
|
||||
| tx | LOUDS trie | 113 | 233 | 3523 | 3147 |
|
||||
| marisa | LOUDS nested patricia trie | 87 | 558 | 1311 | 1041 |
|
||||
| fst | Fast succinct prefix trie | 161 | 519 | 1201 | n/a |
|
||||
| pdt | Centroid path-decomposed trie with RePair | 94 | 2393 | 1453 | 1681 |
|
||||
| hat-trie | HAT-trie | 443 | 275 | 322 | n/a |
|
||||
| array-hash | Array hashing | 693 | 891 | 411 | n/a |
|
||||
|
||||
1. I don't know why, but dastrie did not complete the build.
|
||||
|
||||
#### Table: Url
|
||||
|
||||
| Library | Data structure | Memory (MiB) | Build (ns/key) | Lookup (ns/key) | Decode (ns/id) |
|
||||
| ----------- | ----------------------------------------- | -----------: | -------------: | --------------: | -------------: |
|
||||
| xcdat<8> | XCDA prefix trie | 19 | 606 | 469 | 685 |
|
||||
| xcdat<16> | XCDA prefix trie | 24 | 633 | 461 | 682 |
|
||||
| xcdat<7> | XCDA prefix trie | 19 | 605 | 542 | 772 |
|
||||
| xcdat<15> | XCDA prefix trie | 23 | 624 | 423 | 625 |
|
||||
| darts | Double-array trie | 131 | 2659 | 366 | n/a |
|
||||
| darts-clone | Compact double-array trie | 61 | 1045 | 411 | n/a |
|
||||
| cedar | Dynamic double-array reduced trie | 122 | 287 | 403 | n/a |
|
||||
| cedarpp | Dynamic double-array prefix trie | 49 | 220 | 442 | n/a |
|
||||
| dastrie | Compact double-array prefix trie | 35 | 1009 | 381 | n/a |
|
||||
| tx | LOUDS trie | 21 | 887 | 6389 | 6058 |
|
||||
| marisa | LOUDS nested patricia trie | 9 | 1261 | 1789 | 1747 |
|
||||
| fst | Fast succinct prefix trie | 15 | 1692 | 1948 | n/a |
|
||||
| pdt | Centroid path-decomposed trie with RePair | 10 | 5385 | 1013 | 1287 |
|
||||
| hat-trie | HAT-trie | 48 | 541 | 235 | n/a |
|
||||
| array-hash | Array hashing | 65 | 868 | 268 | n/a |
|
||||
|
||||
## Licensing
|
||||
|
||||
|
|
@ -536,13 +675,22 @@ If you use the library in academic settings, please cite the following paper.
|
|||
|
||||
## References
|
||||
|
||||
1. M. A. Martínez-Prieto, N. Brisaboa, R. Cánovas, F. Claude, and G. Navarro. Practical compressed string dictionaries. Information Systems, 56:73–108, 2016
|
||||
2. S. Kanda, K. Morita, and M. Fuketa. Compressed double-array tries for string dictionaries supporting fast lookup. Knowledge and Information Systems, 51(3): 1023–1042, 2017.
|
||||
3. J. Aoe. An efficient digital search algorithm by using a double-array structure. IEEE Transactions on Software Engineering, 15(9):1066–1077, 1989.
|
||||
4. S. Yata, M. Oono, K. Morita, M. Fuketa, T. Sumitomo, and J. Aoe. A compact static double-array keeping character codes. Information Processing & Management, 43(1):237–247, 2007.
|
||||
5. Müller, Ingo, Cornelius Ratsch, and Franz Faerber. Adaptive string dictionary compression in in-memory column-store database systems. In EDBT, pp. 283–294, 2014.
|
||||
6. Gog, Simon, Giulio Ermanno Pibiri, and Rossano Venturini. Efficient and effective query auto-completion. In SIGIR, pp. 2271–2280, 2020.
|
||||
7. Ricardo Baeza-Yates, and Berthier Ribeiro-Neto. Modern Information Retrieval. 2nd ed. Addison Wesley, Boston, MA, USA, 2011.
|
||||
8. Kudo, Taku, et al. Efficient dictionary and language model compression for input method editors. In WTIM, pp. 19–25, 2011.
|
||||
9. N. R. Brisaboa, S. Ladra, and G. Navarro. DACs: Bringing direct access to variable-length codes. Information Processing & Management, 49(1):392–404, 2013.
|
||||
1. M. A. Martínez-Prieto, N. Brisaboa, R. Cánovas, F. Claude, and G. Navarro. **Practical compressed string dictionaries.** *Information Systems*, 56:73–108, 2016.
|
||||
2. S. Kanda, K. Morita, and M. Fuketa. **Compressed double-array tries for string dictionaries supporting fast lookup.** *Knowledge and Information Systems*, 51(3): 1023–1042, 2017.
|
||||
3. J. Aoe. **An efficient digital search algorithm by using a double-array structure.** *IEEE Transactions on Software Engineering*, 15(9): 1066–1077, 1989.
|
||||
4. S. Yata, M. Oono, K. Morita, M. Fuketa, T. Sumitomo, and J. Aoe. **A compact static double-array keeping character codes.** *Information Processing & Management*, 43(1): 237–247, 2007.
|
||||
5. I. Mülle, R. Cornelius, and F. Franz. **Adaptive string dictionary compression in in-memory column-store database systems.** In *Proc. EDBT*, pp. 283–294, 2014.
|
||||
6. S. Gog, GE. Pibiri, and R. Venturini. **Efficient and effective query auto-completion.** In *Proc. SIGIR*, pp. 2271–2280, 2020.
|
||||
7. R. Baeza-Yates, and B. Ribeiro-Neto. **Modern Information Retrieval.** 2nd ed. Addison Wesley, Boston, MA, USA, 2011.
|
||||
8. T. Kudo, T. Hanaoka, J. Mukai, Y. Tabata, and H. Komatsu. **Efficient dictionary and language model compression for input method editors.** In *Proc. WTIM*, pp. 19–25, 2011.
|
||||
9. N. R. Brisaboa, S. Ladra, and G. Navarro. **DACs: Bringing direct access to variable-length codes.** *Information Processing & Management*, 49(1): 392–404, 2013.
|
||||
10. S. Yata, M. Oono, K. Morita, M. Fuketa, T. Sumitomo, and J. Aoe. **A compact static double-array keeping character codes.** *Information processing & management*, 43(1): 237-247, 2007.
|
||||
11. S. Yata, M. Tamura, K. Morita, M. Fuketa and J. Aoe. **Sequential insertions and performance evaluations for double-arrays.** In *Proc. IPSJ*, pp. 1263–1264, 2009.
|
||||
12. N. Yoshinaga, and M. Kitsuregawa. **A self-adaptive classifier for efficient text-stream processing.** In *Proc. COLING*, pp. 1091–1102, 2014.
|
||||
13. G. Jacobson. **Space-efficient static trees and graphs.** In *Proc. FOCS*, pp. 549–554, 1989.
|
||||
14. S. Yata. **Dictionary compression by nesting prefix/patricia tries.** In *Proc. JNLP*, pp. 576–578, 2011.
|
||||
15. H. Zhang, H. Lim, V. Leis, DG. Andersen, M. Kaminsky, K. Keeton, and A. Pavlo. **Surf: Practical range query filtering with fast succinct tries.** In *Proc. SIGMOD*, pp. 323–336, 2018.
|
||||
16. R. Grossi, and G. Ottaviano. **Fast compressed tries through path decompositions.** *ACM Journal of Experimental Algorithmics*, 19, 2015.
|
||||
17. N. Askitis, and R. Sinha. **Engineering scalable, cache and space efficient tries for strings.** *The VLDB Journal*, *19*(5): 633-660, 2010.
|
||||
18. N. Askitis, and J. Zobel. **Cache-conscious collision resolution in string hash tables.** In *Proc. SPIRE*, pp. 91–102, 2005.
|
||||
|
||||
|
|
|
|||
Loading…
Reference in a new issue